RDK LeRobot Tools
Feishu Document: https://horizonrobotics.feishu.cn/docx/HSr8dBdZ0oQ5OwxPQvBcsuyZnWe
Github README & README_cn: https://github.com/D-Robotics/rdk_LeRobot_tools
D-Robotics Developer Community Chinese Blog:
D-Robotics Developer Community English Blog:
- RDK LeRobot Tools
- Abstract
- Overview of the Entire Process
- 1. Tooling Setup
- 2. Calibration (Calibrate Robot)
- 3. Teleoperation
- 4. Record a Dataset
- 5. Train a Policy
- 6. Run on CPU
- 7. Model Export (ONNX Export)
- 8. Model Quantization and Compilation
- 9. Model Deployment on BPU (Run on BPU)
- Cloth Folding Case Study
- Appendix 1: Algorithm Analysis
- Appendix 2: BPU Deployment Analysis
- Appendix 3: Using MiniConda Virtual Environment
- Appendix 4: Troubleshooting
- Postscript
Abstract
Highlights
- End-to-end robotic arm case study on RDK devices, showcasing ACT Policy: an embodied algorithm for attention from visual space to action space.
- Fully utilizes RDK’s BPU acceleration capabilities for end-to-end speedup.
- Hugging Face community is active, LeRobot is a popular project with significant influence domestically and internationally, offering a complete workflow from dataset collection, training, toolchain quantization, to BPU deployment.
Single Arm SO100 Performance Comparison
This guide enables you to implement LeRobot’s ACT Policy algorithm on RDK devices and observe how BPU acceleration eliminates action generation latency. The following videos are unedited and without acceleration.
RDK S100: Run on CPU
Video: [https://github.com/D-Robotics/rdk_LeRobot_tools/blob/main/imgs/so100_1arm_RunOnCPU.mp4]
RDK S100: Run on BPU
Video: [https://github.com/D-Robotics/rdk_LeRobot_tools/blob/main/imgs/so100_1arm_RunOnBPU.mp4]
Dual Arm SO100 Performance Comparison
You can even assemble a dual-arm SO100 setup and use LeRobot on RDK to tackle tasks like folding clothes!
RDK S100: Run on CPU
Video: [https://github.com/D-Robotics/rdk_LeRobot_tools/blob/main/imgs/so100_2arm_RunOnCPU.mp4]
RDK S100: Run on BPU:
Video: [https://github.com/D-Robotics/rdk_LeRobot_tools/blob/main/imgs/so100_2arm_RunOnBPU.mp4]
We collected 50 sets of dual-arm cloth folding datasets. You can refer to our HuggingFace repository to decide on your dual-arm setup.
Video: [https://github.com/D-Robotics/rdk_LeRobot_tools/blob/main/imgs/dataset_5X6.mp4]
Overview of the Entire Process
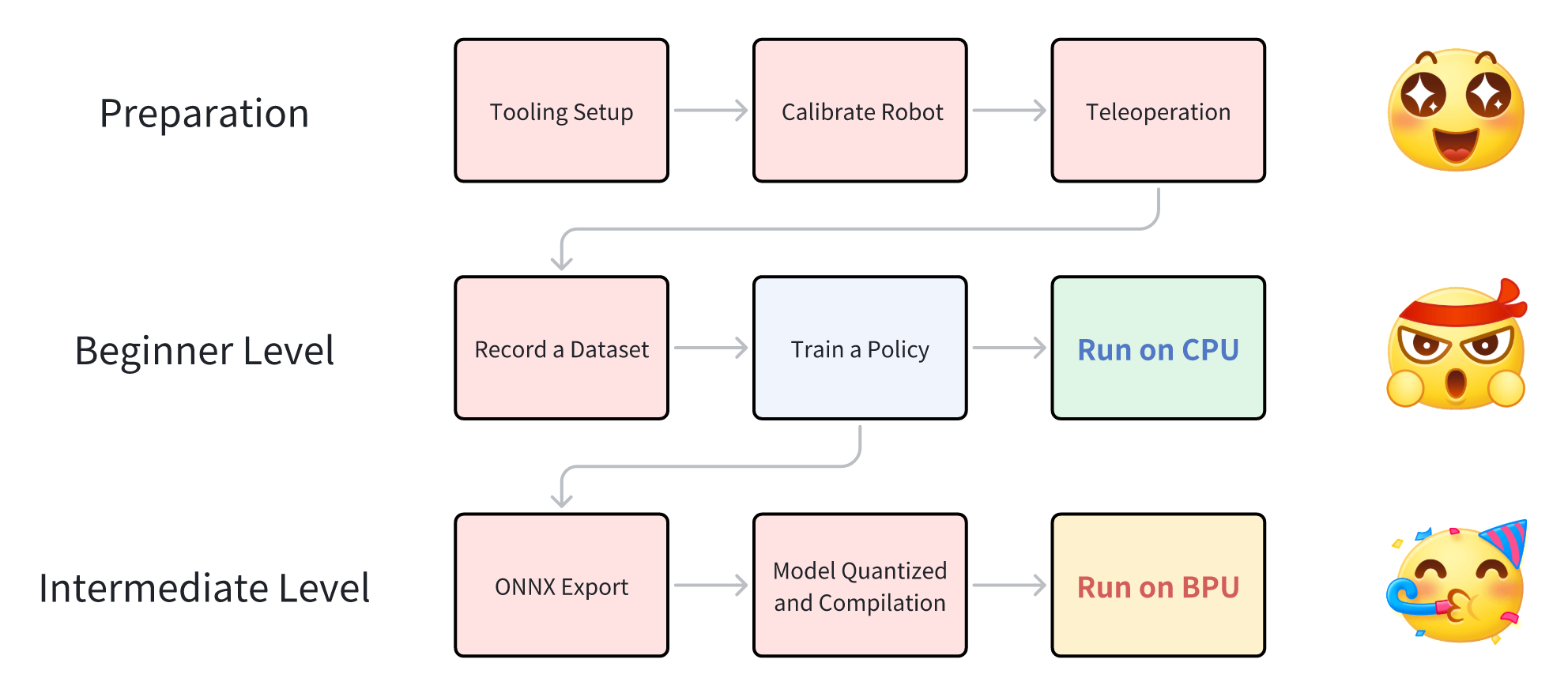
1. Tooling Setup
For tooling setup, refer to the documentation provided by HuggingFace’s LeRobot project: https://github.com/huggingface/lerobot/blob/main/examples/10_use_so100.md
Material Preparation
Below is the list of materials required for a complete SO100 master-slave arm setup. Refer to the complete documentation provided by SO-ARM100 for material preparation: https://github.com/TheRobotStudio/SO-ARM100
D-Robotics
images
links
RDK S100

https://developer.d-robotics.cc/rdks100
RDK X5

https://developer.d-robotics.cc/rdkx5
Software Environment Installation and Setup
If you plan to upload datasets and models to HuggingFace or fetch resources from HuggingFace, configure the terminal proxy accordingly; otherwise, HuggingFace will be inaccessible.
Development Machine Software Environment
-
Prepare a Miniconda environment (optional)
Install the corresponding version of Miniconda, then source it
Installing Miniconda - Anaconda
Create a conda environment
conda create -y -n lerobot python=3.10
Activate the virtual environment
conda activate lerobot
-
It is recommended to download the forked LeRobot repository from the D-Robotics organization. In principle, you can download the public version of the LeRobot repository for model training.
git clone GitHub - D-Robotics/lerobot # Recommend
git clone GitHub - huggingface/lerobot: 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning # or -
After cloning, run the following commands to install the LeRobot repository:
conda install ffmpeg -c conda-forge # If using a conda environment
cd ~/lerobot && pip install -e “.[feetech]”
RDK Board Software Environment
-
Miniconda environment installation on RDK boards is detailed in the appendix (optional).
Create a conda environment
conda create -y -n lerobot python=3.10
Activate the virtual environment
conda activate lerobot
-
It is recommended to download the forked LeRobot repository from the D-Robotics organization. In principle, you can download the public version of LeRobot. All development is based on the forked public version of the LeRobot repository by D-Robotics. D-Robotics has made minimal changes to the public version of LeRobot, and all BPU-related operations are conducted in the newly added
rdk_LeRobot_toolssubfolder.git clone GitHub - D-Robotics/lerobot # Recommend
git clone GitHub - huggingface/lerobot: 🤗 LeRobot: Making AI for Robotics more accessible with end-to-end learning # or -
Download the
rdk_LeRobot_toolsrepository as a subfolder of the LeRobot project.cd lerobot
git clone GitHub - D-Robotics/rdk_LeRobot_tools: BPU Tools for LeRobot. -
After cloning, run the following commands to install the LeRobot repository. Refer to the official documentation
lerobot/examples/10_use_so100.mdfor details.conda install ffmpeg -c conda-forge # If using a conda environment
cd lerobot && pip install -e “.[feetech]”
Modifications Based on the Public Version of LeRobot
-
All operations are based on the
lerobotrepository directory, which contains thelerobotdirectory as a package. Most modifications involve adding configuration files rather than altering the source code of LeRobot. -
Added
rdk_lerobot_tools/cpu_act_control_robot.pyas the entry point for ACT Policy CPU inference. -
Added
rdk_lerobot_tools/bpu_act_control_robot.pyas the entry point for ACT Policy BPU inference. -
Added
rdk_lerobot_tools/export_bpu_actpolicy.pyfor exporting ACT Policy to ONNX, preparing calibration data, YAML files, and BPU model quantization and compilation scripts. -
Modified the
lerobot/lerobot/common/datasets/video_utils.pyfile in theencode_video_framesmethod to adapt to video formats on RDK. Changedlibsvtav1tolibx264.def encode_video_frames(
imgs_dir: Path | str,
video_path: Path | str,
fps: int,
vcodec: str = “libx264”, # Change libsvtav1 → libx264 here
pix_fmt: str = “yuv420p”,
g: int | None = 2,
crf: int | None = 30,
fast_decode: int = 0,
log_level: str | None = “error”,
overwrite: bool = False,
) → None: -
Modified the
lerobot/common/robot_devices/cameras/opencv.pyfile in theconnectmethod to prioritize MJPG format.After initializing the object with self.camera = cv2.VideoCapture(camera_idx, backend), add:
self.camera.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc(‘M’,‘J’,‘P’,‘G’)).
‘…’
self.camera = cv2.VideoCapture(camera_idx, backend)Add the following:
self.camera.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc(‘M’,‘J’,‘P’,‘G’))
‘…’ -
Modified the
lerobot/common/robot_devices/robots/manipulator.pyfile in theset_so100_robot_presetmethod to set the D parameter in PID control to 0, effectively reducing robotic arm jitter during teleoperation.def set_so100_robot_preset(self):
for name in self.follower_arms:
self.follower_arms[name].write(“Mode”, 0)
self.follower_arms[name].write(“P_Coefficient”, 16)
self.follower_arms[name].write(“I_Coefficient”, 0)
self.follower_arms[name].write(“D_Coefficient”, 0) #<— Modify here
self.follower_arms[name].write(“Lock”, 0)
self.follower_arms[name].write(“Maximum_Acceleration”, 254)
self.follower_arms[name].write(“Acceleration”, 254)
Assembling the Robotic Arm & Servo Motor Labeling
Servo Motor Labeling
-
Connect the power and USB port of a servo motor driver board, then run the following command to find the robotic arm’s serial port.
python lerobot/scripts/find_motors_bus_port.py
-
On RDK boards, the serial port typically appears as
/dev/ttyACM0. Run the following command to grant permissions.sudo chmod 666 /dev/ttyACM0
-
Insert your first motor and run this script to set its ID to 1. It will also set the current position to 2048, causing the motor to rotate. Repeat this process for the remaining six motors. Each group consists of six motors, with a total of 12 motors to label. Note: Labeling data is stored in the motor’s internal memory.
python lerobot/scripts/configure_motor.py
–port /dev/ttyACM0
–brand feetech
–model sts3215
–baudrate 1000000
–ID 1
Assembling the Robotic Arm
Refer to the official documentation robot/examples/10_use_so100.md to complete the robotic arm assembly. The assembled robotic arm should look like the images below.



2. Calibration (Calibrate Robot)
-
Ensure that the servo motors are correctly labeled and the robotic arms are assembled in the correct order. Connect the power and USB ports for both robotic arms, then run the following command to identify the device ports:
python lerobot/scripts/find_motors_bus_port.py
-
Update the device ports in the
so100class withinlerobot/lerobot/common/robot_devices/robots/configs.py:@RobotConfig.register_subclass(“so100”)
@dataclass
class So100RobotConfig(ManipulatorRobotConfig):
calibration_dir: str = “.cache/calibration/so100”
max_relative_target: int | None = None
leader_arms: dict[str, MotorsBusConfig] = field(
default_factory=lambda: {
“main”: FeetechMotorsBusConfig(
port=“/dev/ttyACM0”, # Update this based on the identified port
motors={
“shoulder_pan”: [1, “sts3215”],
“shoulder_lift”: [2, “sts3215”],
“elbow_flex”: [3, “sts3215”],
“wrist_flex”: [4, “sts3215”],
“wrist_roll”: [5, “sts3215”],
“gripper”: [6, “sts3215”],
},
),
}
)follower_arms: dict[str, MotorsBusConfig] = field( default_factory=lambda: { "main": FeetechMotorsBusConfig( port="/dev/ttyACM1", # Update this based on the identified port motors={ "shoulder_pan": [1, "sts3215"], "shoulder_lift": [2, "sts3215"], "elbow_flex": [3, "sts3215"], "wrist_flex": [4, "sts3215"], "wrist_roll": [5, "sts3215"], "gripper": [6, "sts3215"], }, ), } ) cameras: dict[str, CameraConfig] = field( default_factory=lambda: { "laptop": OpenCVCameraConfig( camera_index=2, fps=30, width=640, height=480, ), "phone": OpenCVCameraConfig( camera_index=0, fps=30, width=640, height=480, ), } ) mock: bool = False -
Ensure both robotic arms are connected, then run the following scripts to start manual calibration:
Calibrate the follower arm:
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--robot.cameras='{}' \
--control.type=calibrate \
--control.arms='["main_follower"]'

Calibrate the leader arm:
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--robot.cameras='{}' \
--control.type=calibrate \
--control.arms='["main_leader"]'

3. Teleoperation
Before starting teleoperation or data collection, run the following command to confirm the robotic arm port numbers:
python lerobot/scripts/find_motors_bus_port.py
If there are any changes, update the corresponding ports in the so100 class within lerobot/common/robot_devices/robots/configs.py:
@RobotConfig.register_subclass("so100")
@dataclass
class So100RobotConfig(ManipulatorRobotConfig):
calibration_dir: str = ".cache/calibration/so100"
max_relative_target: int | None = None
leader_arms: dict[str, MotorsBusConfig] = field(
default_factory=lambda: {
"main": FeetechMotorsBusConfig(
port="/dev/ttyACM0", #<-------Update this for the leader arm port
motors={
"shoulder_pan": [1, "sts3215"],
"shoulder_lift": [2, "sts3215"],
"elbow_flex": [3, "sts3215"],
"wrist_flex": [4, "sts3215"],
"wrist_roll": [5, "sts3215"],
"gripper": [6, "sts3215"],
},
),
}
)
follower_arms: dict[str, MotorsBusConfig] = field(
default_factory=lambda: {
"main": FeetechMotorsBusConfig(
port="/dev/ttyACM1", #<-------Update this for the follower arm port
motors={
"shoulder_pan": [1, "sts3215"],
"shoulder_lift": [2, "sts3215"],
"elbow_flex": [3, "sts3215"],
"wrist_flex": [4, "sts3215"],
"wrist_roll": [5, "sts3215"],
"gripper": [6, "sts3215"],
},
),
}
)
cameras: dict[str, CameraConfig] = field(
......
)
mock: bool = False
Once the port numbers are correctly configured, run the following command to start teleoperation without cameras:
python lerobot/scripts/control_robot.py \
--robot.type=so100 \
--robot.cameras='{}' \
--control.type=teleoperate
4. Record a Dataset
-
Attach two USB cameras to capture the robot arm’s perspective and an external fixed perspective. Insert the USB cameras into the RDK and run the following script to check the camera port indices. Ensure that
lerobot/common/robot_devices/cameras/opencv.pyhas been modified to prioritize MJPG images.python lerobot/common/robot_devices/cameras/opencv.py
–images-dir outputs/images_from_opencv_cameras
The terminal will display the following information:
Linux detected. Finding available camera indices through scanning '/dev/video*' ports
[...]
Camera found at index /dev/video2
Camera found at index /dev/video0
Connecting cameras
OpenCVCamera(2, fps=30, width=640, height=480, color_mode=rgb)
OpenCVCamera(0, fps=30, width=640, height=480, color_mode=rgb
Frame: 0000 Latency (ms): 39.52
[...]
Frame: 0102 Latency (ms): 40.07
Images have been saved to outputs/images_from_opencv_cameras
-
Locate the images captured by each camera in the
outputs/images_from_opencv_camerasdirectory and confirm the port indices corresponding to each camera’s position. -
Update the camera parameters in the
lerobot/lerobot/common/robot_devices/robots/configs.pyfile to align with the identified indices:@RobotConfig.register_subclass(“so100”)
@dataclass
class So100RobotConfig(ManipulatorRobotConfig):
calibration_dir: str = “.cache/calibration/so100”
max_relative_target: int | None = Noneleader_arms: dict[str, MotorsBusConfig] = field( default_factory=lambda: { "main": FeetechMotorsBusConfig( port="/dev/ttyACM0", motors={ "shoulder_pan": [1, "sts3215"], "shoulder_lift": [2, "sts3215"], "elbow_flex": [3, "sts3215"], "wrist_flex": [4, "sts3215"], "wrist_roll": [5, "sts3215"], "gripper": [6, "sts3215"], }, ), } ) follower_arms: dict[str, MotorsBusConfig] = field( default_factory=lambda: { "main": FeetechMotorsBusConfig( port="/dev/ttyACM1", motors={ "shoulder_pan": [1, "sts3215"], "shoulder_lift": [2, "sts3215"], "elbow_flex": [3, "sts3215"], "wrist_flex": [4, "sts3215"], "wrist_roll": [5, "sts3215"], "gripper": [6, "sts3215"], }, ), } ) cameras: dict[str, CameraConfig] = field( default_factory=lambda: { "laptop": OpenCVCameraConfig( camera_index=0, # Update this with the robot arm camera ID and parameters fps=30, width=640, height=480, ), "phone": OpenCVCameraConfig( camera_index=2, # Update this with the external perspective camera ID and parameters fps=30, width=640, height=480, ), } ) mock: bool = False -
Begin data collection by running the following script:
python lerobot/scripts/control_robot.py
–robot.type=so100
–control.type=record
–control.fps=30
–control.single_task=“Cloth Fold”
–control.tags=‘[“so100”,“tutorial”]’
–control.warmup_time_s=5
–control.episode_time_s=30
–control.reset_time_s=1
–control.num_episodes=50
–control.push_to_hub=false
–control.display_data=false
–control.repo_id=USER/so100_test
–control.root=datasets/so100_test
Parameter explanations:
warmup-time-s: Initialization time.episode-time-s: Duration of each data collection session.reset-time-s: Preparation time between sessions.num-episodes: Number of data collection sessions.push-to-hub: Whether to upload the dataset to HuggingFace Hub.display_data: Whether to display a graphical interface.root: Path to save the dataset.
- Recommendations for dataset recording:
Once you are familiar with recording data, you can create a larger dataset for training. A good starting task is to pick up an object from different locations and place it in a box. We recommend recording at least 50 sessions, with 10 sessions per location. Keep the cameras fixed and maintain consistent grasping behavior throughout the recording process.
In the next steps, you will train your neural network. After achieving reliable grasping performance, you can introduce more variations during data collection, such as additional grasping locations, different grasping techniques, and changing camera positions. Avoid introducing too many variations too quickly, as it may negatively impact your results.
-
To visualize the dataset locally, use the following command:
python lerobot/scripts/visualize_dataset_html.py
–repo-id USER/so100_test
–root datasets/so100_test # Specify the dataset path
5. Train a Policy
Transfer Dataset to Development Machine
-
If your development machine is configured with a proxy and the dataset has been pushed to HuggingFace, you can load the dataset during training using the
repo_idparameter. Ensure you are logged into HuggingFace on the development machine. -
If no proxy is configured and the dataset is stored locally, move the dataset to the development machine under
~/.cache/huggingface/lerobot/USERor specify the dataset path using thedataset.rootparameter. The author used a TITAN Xp GPU, and training 50 sessions of 60-second operation data for 50k iterations with a batch size of 8 took approximately 4 hours. -
Enable
wandb(optional) and log in to monitor training progress:wandb login
-
Start training by running the following script. Modify training parameters in the
lerobot/configs/train.pyfile as needed:python lerobot/scripts/train.py
–dataset.repo_id=USER/so100_test \ # Replace with your dataset
–policy.type=act
–output_dir=outputs/train/act_test_1epoch
–job_name=act_so100_test
–policy.device=cuda
–wandb.enable=true
–dataset.root=…
Parameter explanations:
policy.type: Type of policy to use.output_dir: Path to save the trained model.job_name: Name of the training job.policy.device: Device to use for training.wandb.enable: Whether to enablewandb.dataset.root: Path to the dataset.
Monitor Training Progress
When --wandb.enable=true is set, you can view the training curves on the wandb dashboard.
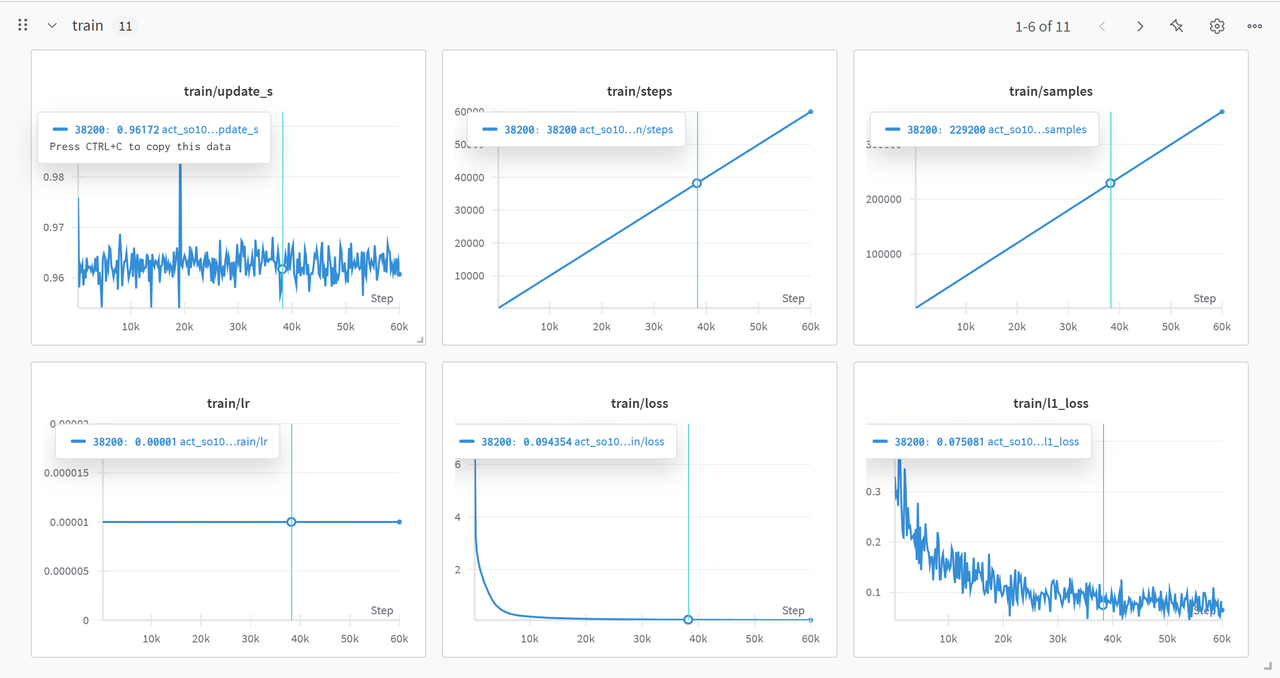
Analyze Training Results
-
update_s: The curve fluctuates but remains stable overall. Occasional spikes may indicate anomalies in computation or resource scheduling during training. -
steps&samples: Both increase linearly, indicating that training progresses as expected, with a stable number of samples processed per step. -
lr: The learning rate remains constant, allowing the model to converge quickly during the early stages of training. -
loss: The loss decreases rapidly at first and then stabilizes at a low value, indicating effective learning of data features and nearing convergence. -
l1_loss: Gradually decreases with fluctuations, showing that the model is optimizing the absolute error between predictions and ground truth but has not fully stabilized.
6. Run on CPU
-
You can simply use a script to load the model and perform inference:
Update the script with the correct model weight directory
python rdk_lerobot_tools/cpu_control_robot.py
-
Alternatively, you can use the
control_robot.pyscript with therecordmethod to perform inference and simultaneously record evaluation datasets:python lerobot/scripts/control_robot.py
–robot.type=so100
–control.type=record
–control.fps=30
–control.single_task=“Cloth Fold”
–control.repo_id=MaCCChhh/eval_act_so100_0418_test1
–control.tags=‘[“tutorial”]’
–control.warmup_time_s=5
–control.episode_time_s=180
–control.reset_time_s=30
–control.num_episodes=10
–control.push_to_hub=false
–control.policy.path=outputs/act_so100_resnet152_0418_test1/pretrained_model
You should observe the robotic arm operating as expected. If your training was successful, the robotic arm will mimic the actions recorded earlier. However, it may pause intermittently during operation. Don’t worry; we will use the BPU to accelerate policy generation and eliminate these pauses.

7. Model Export (ONNX Export)
Export the LeRobot safetensors model to ONNX and prepare calibration data. After training with LeRobot, you will typically have the following folder structure:
./pretrained_model/
├── config.json
├── model.safetensors
└── train_config.json
Use the rdk_lerobot_tools/export_bpu_actpolicy.py script to prepare calibration data. Update the script with the path to the floating-point weights and other parameters, starting around line 51:
parser = argparse.ArgumentParser()
parser.add_argument('--act-path', type=str, default='lerobot_training_weights/act_0417_2arms-', help='Path to LeRobot ACT Policy model.')
"""
# example: --act-path pretrained_model
./pretrained_model/
├── config.json
├── model.safetensors
└── train_config.json
"""
parser.add_argument('--export-path', type=str, default='bpu_act_0417_2arms', help='Path to save LeRobot ACT Policy model.')
parser.add_argument('--cal-num', type=int, default=200, help='Num of images to generate')
parser.add_argument('--onnx-sim', type=bool, default=True, help='Simplify onnx or not.')
parser.add_argument('--type', type=str, default="nash-e", help='Optional: nash-e, nash-m, nash-p, bayes, bayes-e')
parser.add_argument('--combine-jobs', type=int, default=6, help='combie jobs for OpenExplore.')
opt = parser.parse_args([])
Ensure the parameters match those used during training. Typically, you need to update the --dataset.repo_id parameter to specify the dataset used. This export script, based on the training script, will export the model to ONNX and prepare calibration data.
python rdk_lerobot_tools/export_bpu_actpolicy.py \
--dataset.repo_id=MaCCChhh/so100_0417_test1 \
--policy.type=act \
--policy.device=cpu \
--wandb.enable=false
If successful, you will see the following log:
8. Model Quantization and Compilation
After exporting the model, you will have a BPU compilation workspace with the following structure. The ACT Policy’s vision encoder and 4+1 Transformer layers are exported separately. Calibration data is saved based on the training dataset, and scripts and YAML files for compilation are generated. Pre- and post-processing parameters for image and action inputs are saved as .npy files in the final BPU release folder.
.
├── BPU_ACTPolicy_TransformerLayers
│ ├── BPU_ACTPolicy_TransformerLayers.onnx
│ ├── build_BPU_ACTPolicy_TransformerLayers.sh
│ ├── calibration_data_BPU_ACTPolicy_TransformerLayers
│ ├── config_BPU_ACTPolicy_TransformerLayers.yaml
├── BPU_ACTPolicy_VisionEncoder
│ ├── BPU_ACTPolicy_VisionEncoder.onnx
│ ├── build_BPU_ACTPolicy_VisionEncoder.sh
│ ├── calibration_data_BPU_ACTPolicy_VisionEncoder
│ ├── config_BPU_ACTPolicy_VisionEncoder.yaml
├── bpu_output_act_0417_2arms
│ ├── action_mean.npy
│ ├── action_mean_unnormalize.npy
│ ├── action_std.npy
│ ├── action_std_unnormalize.npy
│ ├── laptop_mean.npy
│ ├── laptop_std.npy
│ ├── phone_mean.npy
│ └── phone_std.npy
└── build_all.sh
Use the standard Docker environment provided by the algorithm toolchain to complete BPU model quantization and compilation. Use the following command to mount the Docker container:
[sudo] docker run [--gpus all] -it -v <BPU_Work_Space>:/open_explorer REPOSITORY:TAG
Where:
sudois optional, depending on your Docker installation.--gpus allis required for GPU Docker. For CPU Docker, omit this parameter. In the X5 PTQ scheme, use CPU Docker unless using QAT. For S100 PTQ, GPU Docker accelerates calibration but is optional.<BPU_Work_Space>should be replaced with the absolute path to your BPU workspace.REPOSITORY:TAGrefers to the Docker container name and version. Usedocker imagesto confirm.
Note: This is a reference mounting method. You can use any preferred method to run Docker. For further details, refer to the Docker documentation.
9. Model Deployment on BPU (Run on BPU)
After completing model quantization and compilation, you will obtain a bpu_output folder containing the following files:
$ tree bpu_output_act_0417_2arms
.
├── BPU_ACTPolicy_TransformerLayers.hbm
├── BPU_ACTPolicy_VisionEncoder.hbm
├── action_mean.npy
├── action_mean_unnormalize.npy
├── action_std.npy
├── action_std_unnormalize.npy
├── laptop_mean.npy
├── laptop_std.npy
├── phone_mean.npy
└── phone_std.npy
Copy the BPU ACT Policy model to the RDK board and update the path to your bpu_output folder. Note that the model path provided to the BPU_ACTPolicy class should be the folder path. Run the following script to use the BPU for ACT Policy model inference. During each inference, the BPU operates at 100% utilization for 50 milliseconds to generate 50 robotic arm actions. While the actions are being executed, the BPU utilization drops to 0%. Once the 50 actions are completed, the BPU starts the next round of inference.
python rdk_lerobot_tools/bpu_act_control_robot.py
Compared to pure CPU inference, the powerful burst inference capability of the BPU eliminates the latency between actions.
Cloth Folding Case Study
Reference dataset repository ID: https://huggingface.co/datasets/MaCCChhh/rdk_so100_test/tree/main
Online visualization of the reference dataset: https://huggingface.co/spaces/lerobot/visualize_dataset?dataset=MaCCChhh%2Frdk_so100_test
Dual-Arm Setup
-
Material Preparation: Prepare two complete sets of SO100 materials: 2 leader arms, 2 follower arms, and 4 servo motor control boards. Ensure you have enough USB ports; if not, prepare a USB hub.
-
Reassemble SO100: Ensure the servo motors are labeled (servo labels are stored in the internal memory of the motors).
-
Connect Servo Boards: Connect the four servo motor control boards to the RDK and confirm the device ports (servo serial port numbers).
-
Update Configuration: Modify the
so100class inlerobot/lerobot/common/robot_devices/robots/configs.pyas follows:@RobotConfig.register_subclass(“so100”)
@dataclass
class So100RobotConfig(ManipulatorRobotConfig):
calibration_dir: str = “.cache/calibration/so100” # Optional: Modify the calibration folder
max_relative_target: int | None = None
leader_arms: dict[str, MotorsBusConfig] = field( # Update “main” to “left” and “right”
default_factory=lambda: {
“left”: FeetechMotorsBusConfig(
port=“/dev/ttyACM0”, # Update based on device confirmation
motors={
“shoulder_pan”: [1, “sts3215”],
“shoulder_lift”: [2, “sts3215”],
“elbow_flex”: [3, “sts3215”],
“wrist_flex”: [4, “sts3215”],
“wrist_roll”: [5, “sts3215”],
“gripper”: [6, “sts3215”],
},
),
“right”: FeetechMotorsBusConfig(
port=“/dev/ttyACM3”,
motors={
“shoulder_pan”: [1, “sts3215”],
“shoulder_lift”: [2, “sts3215”],
“elbow_flex”: [3, “sts3215”],
“wrist_flex”: [4, “sts3215”],
“wrist_roll”: [5, “sts3215”],
“gripper”: [6, “sts3215”],
},
),
}
)follower_arms: dict[str, MotorsBusConfig] = field( # Update "main" to "left" and "right" default_factory=lambda: { "left": FeetechMotorsBusConfig( port="/dev/ttyACM2", motors={ "shoulder_pan": [1, "sts3215"], "shoulder_lift": [2, "sts3215"], "elbow_flex": [3, "sts3215"], "wrist_flex": [4, "sts3215"], "wrist_roll": [5, "sts3215"], "gripper": [6, "sts3215"], }, ), "right": FeetechMotorsBusConfig( port="/dev/ttyACM4", motors={ "shoulder_pan": [1, "sts3215"], "shoulder_lift": [2, "sts3215"], "elbow_flex": [3, "sts3215"], "wrist_flex": [4, "sts3215"], "wrist_roll": [5, "sts3215"], "gripper": [6, "sts3215"], }, ), } ) cameras: dict[str, CameraConfig] = field( default_factory=lambda: { "laptop": OpenCVCameraConfig( camera_index=5, fps=30, width=640, height=480, ), "phone": OpenCVCameraConfig( camera_index=1, fps=30, width=640, height=480, ), } ) mock: bool = False -
Calibrate Dual Arms: If all four arms have already been calibrated in a single-arm setup, you can skip calibration by renaming the calibration files. Calibration files are stored in
.cache/calibration/so100.python lerobot/scripts/control_robot.py
–robot.type=so100
–robot.cameras=‘{}’
–control.type=calibrate
–control.arms=‘[“left_follower”]’–control.arms=‘[“right_follower”]’
–control.arms=‘[“left_leader”]’
–control.arms=‘[“right_leader”]’
After calibration, you can find the files in the .cache/calibration/so100 directory:
`-- calibration
`-- so100
|-- left_follower.json
|-- left_leader.json
|-- right_follower.json
`-- right_leader.json
-
Test Teleoperation Without Cameras: Run the following script to test dual-arm teleoperation:
python lerobot/scripts/control_robot.py
–robot.type=so100
–robot.cameras=‘{}’
–control.type=teleoperate
Data Collection and Training Deployment
Now that you have completed the dual-arm teleoperation setup, the subsequent steps are the same as for a single-arm setup.
For dataset collection, refer to: https://huggingface.co/spaces/lerobot/visualize_dataset?dataset=MaCCChhh%2Frdk_so100_test
Appendix 1: Algorithm Analysis
Reference Paper: https://arxiv.org/abs/2304.13705
Dataset Recording (Record a Dataset)
Collect RGB images from multiple cameras, current joint positions of the robot, and human operation data (demonstration trajectories collected via teleoperation).


Model Training (Train a Policy)
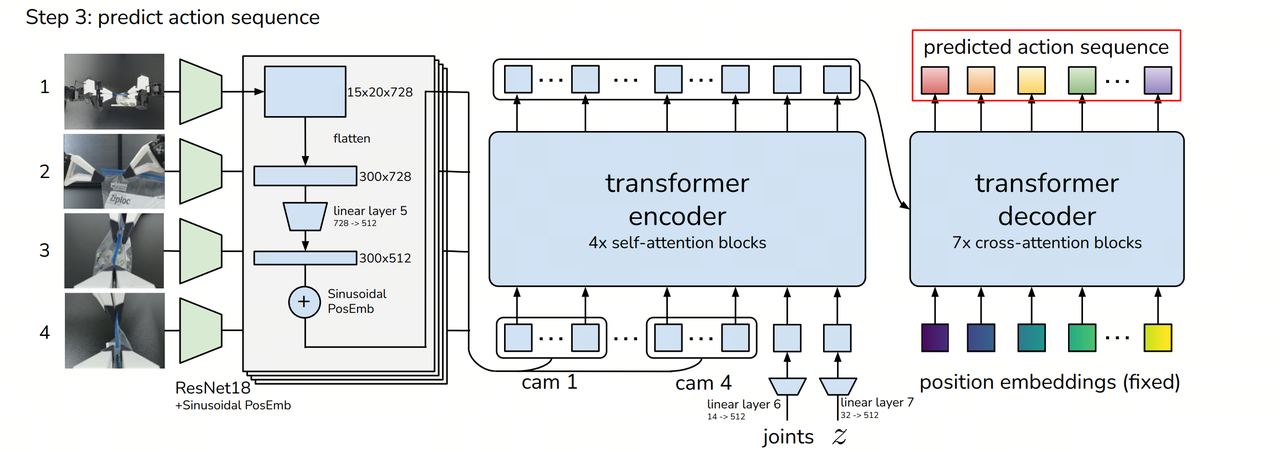
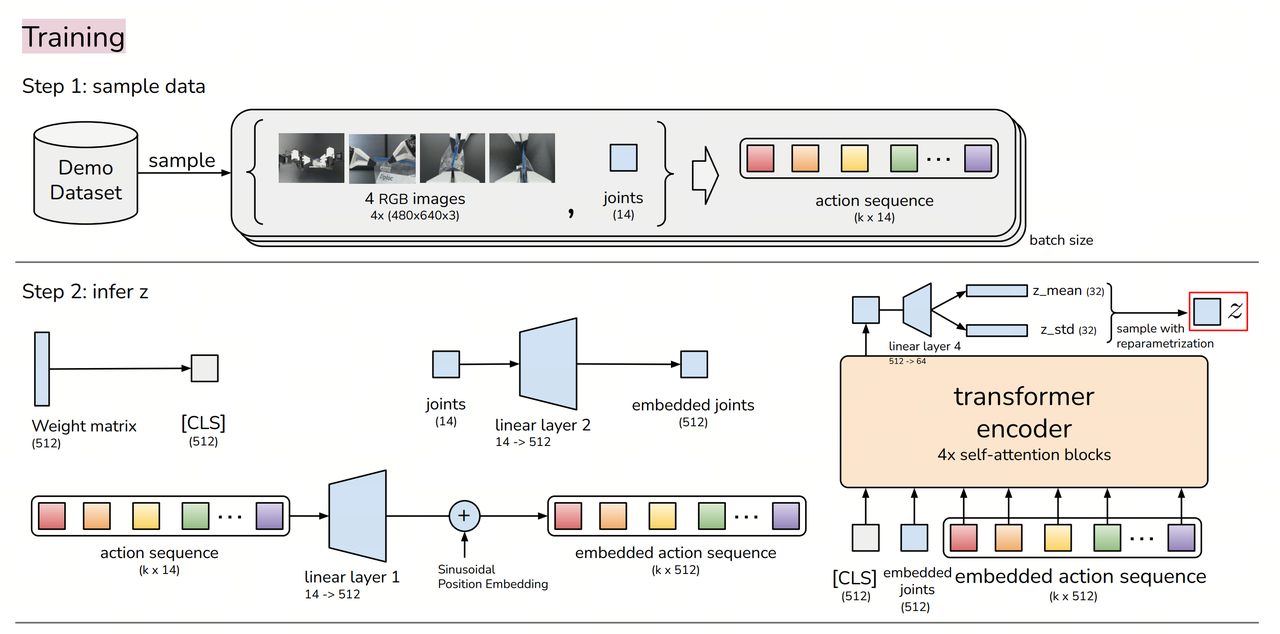

The training objective is to enable the model to predict future k-step action sequences from observation data (images + joint positions) rather than single-step predictions. The core components are as follows:
Encoder (CVAE Encoder):
- Uses a Transformer Encoder to process past actions and state information.
- Generates a latent variable z (style variable) to capture styles and variations in human demonstrations.
Decoder (CVAE Decoder / Transformer Policy):
- Input: Current observation data (images + joint positions) + latent variable z.
- Output: Future k-step action sequences (target joint positions).
Training Loss Functions:
- Reconstruction Loss: Ensures the predicted action sequences are close to the real demonstration data.
- KL Divergence Loss: Forces the latent variable z to follow a standard normal distribution, enhancing generalization.
Training Outcome: A Transformer-based model capable of predicting future k-step actions given current observations.
Model Deployment (Run)
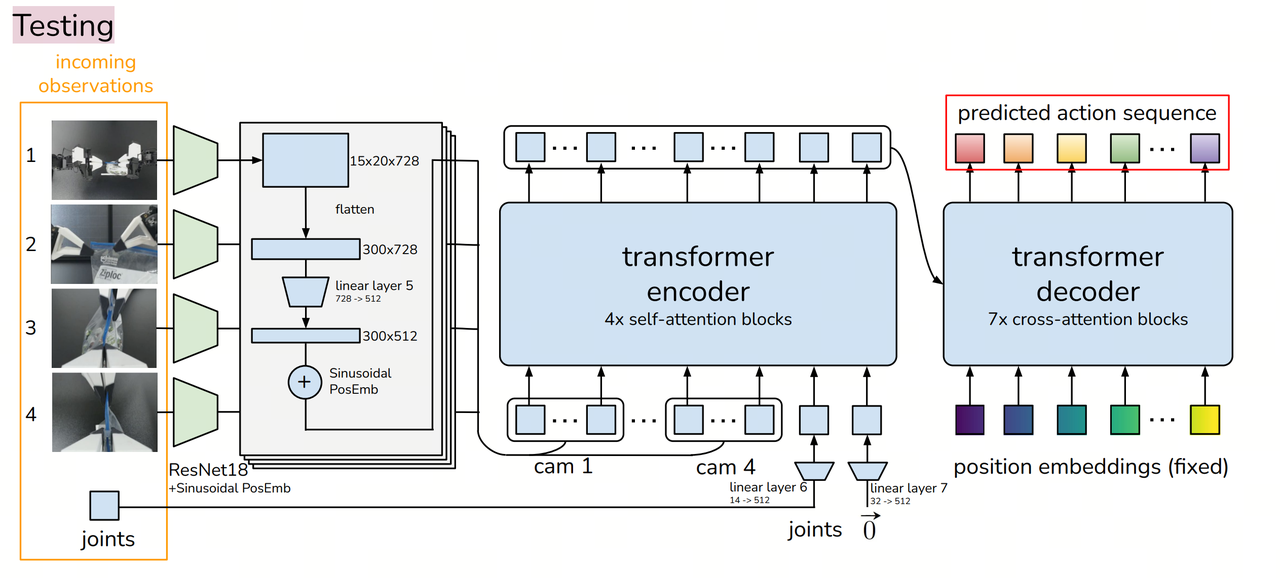

Inputs:
robot_state_feature(optional): Batch of robot states with shape (B, state_dim), where B is the batch size and state_dim is the dimension of the robot state.image_features: Batch of images with shape (B, n_cameras, C, H, W), where B is the batch size, n_cameras is the number of cameras, C is the number of channels (usually 3 for RGB), H is the image height, and W is the image width.env_state_feature: Batch of environment states with shape (B, env_dim), where B is the batch size and env_dim is the dimension of the environment state.action_feature(optional, only used during VAE training): Batch of actions with shape (B, chunk_size, action_dim), where B is the batch size, chunk_size is the length of the action sequence, and action_dim is the dimension of each action.
Outputs:
- Action sequence batch with shape (B, chunk_size, action_dim).
- A tuple containing latent probability density function (PDF) parameters
(mean, log(σ²)), where bothmeanandlog(σ²)are tensors of shape (B, L), and L is the latent dimension.
For example, if B = 32, chunk_size = 10, action_dim = 6, and L = 64, the output action sequence batch will have shape (32, 10, 6), and the latent PDF parameters will have shape (32, 64). During execution, ACT uses inference strategies to smooth predictions and reduce error accumulation.
Action Chunking:
- Instead of predicting single actions step-by-step, the robot predicts k-step action sequences at a time.
- This reduces compounding errors and improves action coherence.
Temporal Ensembling:
- Since multiple k-step predictions may overlap, at a given time step t, there may be multiple predictions.
- Exponential Moving Average (EMA) is used to fuse multiple predictions, improving stability and ensuring smooth robot motion.
Execution Phase:
- The action sequence
a_t, processed by Temporal Ensembling, is sent to the robot for execution. - The robot controller uses PID control to gradually follow the target action sequence.
Appendix 2: BPU Deployment Analysis
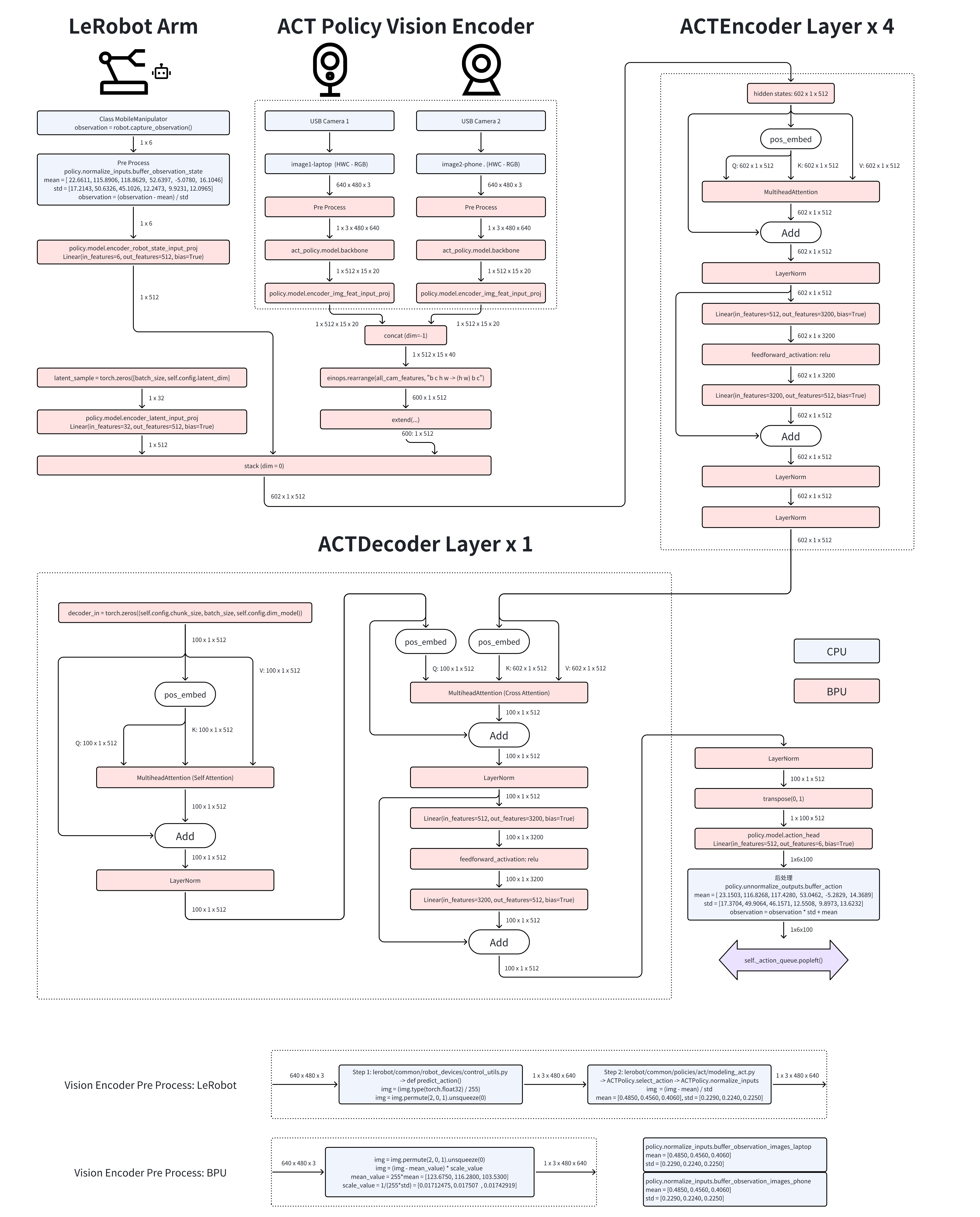
During CPU deployment, Python debugging tools are used to step through the ACT Policy algorithm implemented in Hugging Face’s LeRobot project.
Since the vision encoder is invoked multiple times (once per camera), it is exported separately under the name BPU_ACTPolicy_VisionEncoder. Subsequently, image tokens and action tokens are fed into the encoder and decoder layers, which are exported as BPU_ACTPolicy_TransformerLayers.
Appendix 3: Using MiniConda Virtual Environment
Install MiniConda on RDK X5 / S100 and configure it to use the Tsinghua mirror.
Reference: https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
Download the MiniConda installation script from the Tsinghua mirror. Choose the py310 version to align with the global interpreter version of Ubuntu 22.04.
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py310_25.1.1-2-Linux-aarch64.sh
Run the installation script:
sh Miniconda3-py310_25.1.1-2-Linux-aarch64.sh
Welcome to Miniconda3 py310_25.1.1-2
In order to continue the installation process, please review the license
agreement.
Please, press ENTER to continue
>>>
At this time, press Enter to proceed to the next step. After this, a long string of license will appear. Keep pressing Enter until the following prompt appears.
Do you accept the license terms? [yes|no]
>>>
此时输入 yes 后回车,出现以下提示
Miniconda3 will now be installed into this location:
/root/miniconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/root/miniconda3] >>>
Press Enter or fill in the path you want to install (it is not recommended to modify), and start installation until:
Preparing transaction: done
Executing transaction: done
installation finished.
Do you wish to update your shell profile to automatically initialize conda?
This will activate conda on startup and change the command prompt when activated.
If you'd prefer that conda's base environment not be activated on startup,
run the following command when conda is activated:
conda config --set auto_activate_base false
You can undo this by running `conda init --reverse $SHELL`? [yes|no]
[no] >>>
ress Enter or fill in the path you want to install (it is not recommended to modify), and start installation until:
no change /root/miniconda3/condabin/conda
no change /root/miniconda3/bin/conda
no change /root/miniconda3/bin/conda-env
no change /root/miniconda3/bin/activate
no change /root/miniconda3/bin/deactivate
no change /root/miniconda3/etc/profile.d/conda.sh
no change /root/miniconda3/etc/fish/conf.d/conda.fish
no change /root/miniconda3/shell/condabin/Conda.psm1
no change /root/miniconda3/shell/condabin/conda-hook.ps1
modified /root/miniconda3/lib/pythonNone/site-packages/xontrib/conda.xsh
no change /root/miniconda3/etc/profile.d/conda.csh
modified /root/.bashrc
==> For changes to take effect, close and re-open your current shell. <==
Thank you for installing Miniconda3!
then input
source ~/.bashrc
If the terminal prompt shows (base) at the beginning, the installation was successful:
(base) root@ubuntu:~#
Appendix 4: Troubleshooting
FFmpeg Error Troubleshooting
If you encounter an issue where FFmpeg cannot find the libx264 encoder, it is likely that the precompiled FFmpeg binary you are using was built without GPL components. To resolve this, uninstall the current FFmpeg and install a version that includes GPL support.
# Locate the FFmpeg being used in the current environment
which ffmpeg
# If it is the system FFmpeg [e.g., /usr/bin/ffmpeg]
sudo apt remove ffmpeg
# If it is the FFmpeg from a Conda environment [e.g., /home/user/miniconda3/bin/ffmpeg]
conda remove ffmpeg
Robotic Arm Oscillating at One Position
If the robotic arm oscillates repeatedly at a single position, first verify that the correct model weights are being used. For example, if the model weights are from the early stages of training, the model may not have converged yet. Additionally, if you are using more than two cameras, check whether the camera indices are correct. You can confirm this by reviewing the camera names in the dataset.
Unable to Use Two USB Cameras
Since the RDK X5 chip has only one USB 3.1 port, you need to limit the bandwidth usage of each USB camera for UVC devices. Otherwise, the first camera may consume all the available bandwidth.
rmmod uvcvideo
modprobe uvcvideo quirks=128
If the issue persists, you can try using the following driver patch:
sudo rmmod uvcvideo
sudo insmod uvcvideo.ko
Postscript
Due to the challenges of migrating the solution, some hard-coded configurations were inevitably used, such as the names of the two cameras (phone and laptop) and the fixed input image size of 640x480. It is recommended to first reproduce the setup as described in this document. If you wish to make modifications, such as adding more cameras, changing the camera resolution, or increasing the number of robotic arms, the source code of our solution is fully open. You can customize your deployment plan based on the source code.